The story so far
Yesterday we were discussing our (admittedly) somewhat ghetto, not-quite-batched Neo4j implementation.
The long and short of it is that I was initially attacking the import process as one would on a JDBC client for a relational database. Query for these values here, create those if some don’t exist, insert relationships here, etc.
That seems to be woefully inefficient in Neo4j.
The second approach I tried was to reduce calls for a page to just a handful, following this procedure:
- Start from a page.
- Create a node for it if it doesn’t exist on the database.
- Parse the page, and get all the references to other tropes.
- Import all the nodes that we don’t have already in the database.
- Create an outgoing relationship from the central node to all the nodes it references.
On our test case, this turned out to decrease the import cost from the initial implementation from 52 seconds down to 12. My conclusion was that we’re still getting a significant hit from Neo4j’s writing to the transaction log, which every call up there requires, plus likely missing some indices from the way I had to write the cypher calls.
If we want to stay with Neo4j, our option is to use their batching REST end point. Which will require some serious data -pre-processing.
Meet the new batching
It’s not the same as the old batching, it’s actually using Neo4j’s batch REST end point.
After staring at the data for a bit, I decided the approach needed to be the following:
- Lump together all URLs we need to get - our import set.
- Handle exceptions on retrieving each one independently, so that we can continue importing 9 out of 10 and just mark that 10th one as having a problem if necessary.
- Find which of the import set pages we need to create and which we just need to update the data for.
- For the pages with get errors, only mark them as having an error and log the error.
- Figure out which of the pages from the import set are redirects. In that case we’ll need to create two nodes - one with the original redirector URL, so we don’t try to import it again, and one with the target redirected URL.
- Get all pages to link to from the import set - the link set.
- From the pages to link to, get all of those that do not exist.
- Remove out of those that do not exist the pages we’re about to create or modify because they’re part of the import set (since pages from the import set may link to each other).
- Create all pages from the import and link set.
- For all pages we just created - both import set and link set - add a label.
- Update the existing import set pages.
This yields a more complex workflow than the original plan, since now we’re looking at how pages in our import set relate to each other, but has the potential for being faster.
Our data
Let’s see about testing this with the 10 pages with the most outgoing links we have on the db right now.
MATCH (n)-[r]->() WITH COUNT(r) as c, n
RETURN c, n.id, n.url ORDER BY c DESC LIMIT 10;
This yields:
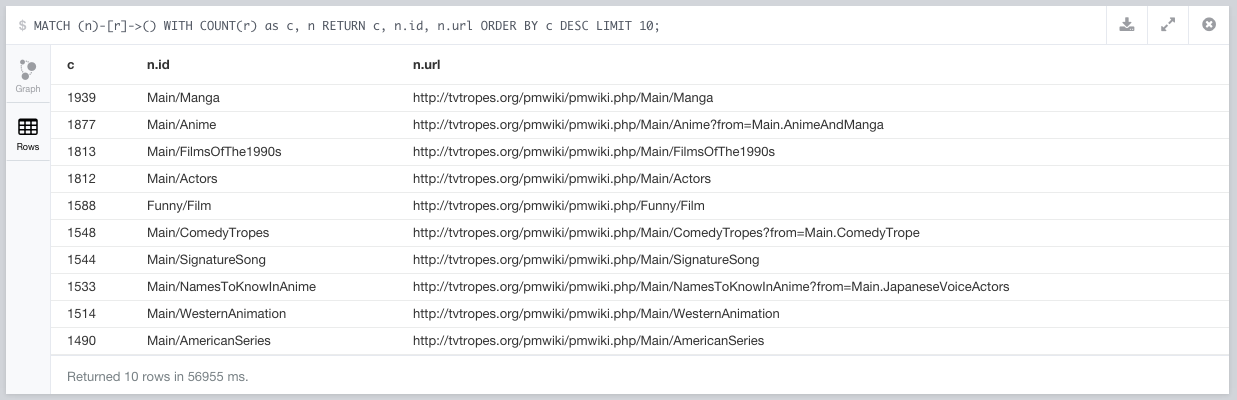
We’ll use them as our test import set.
Changes
As discussed on the last post, I ran into a bit of a modeling issue where sometimes I needed to pass a label value to a cypher query but couldn’t parametrize the labels easily. For now (and probably moving forward) I’ve made the decision to just file all imported nodes into an Article label, so that I don’t have any index missed when I can’t pass the label for an article group.
Also, since we will be querying by for the node id, I’ve renamed our internal id to code to avoid confusion. Will likely re-import the whole database anyway.
Now, not being able to handle each page individually and having to batch everything up obviously will make the code less straightforward. The current version of the import functions looks a bit like this (very much a WIP and not handling redirects yet):
Bear with me here - that’s mostly me thinking out loud as I write tests and figure out the best way to collate the data. However, if you have any improvement suggestions (the to-create-link / to-create-import filters can get expensive) I’d love to hear them on Github.
Having said that, while that is not as short as the trivial per-page Clojure approach, it’s still easy enough to read what’s going on, and it expressed the described workflow well.
The good, the bad, the ugly
Now, this section is going to be an assortment of notes. Here be randomness.
…
Gah. Hair-tearing time. The error you get from Neo4j when you accidentally have a PUT method where you should have POST is not exactly explicit. If you get an obscure error, check you have the right method on the request first.
…
Damn the batch API took a bit to figure out for some reason - perhaps because I had gotten used to Cypher and neocons, and had to start by looking into what the REST endpoint expectations for each thing were myself.
Eventually I end up settling on these for create and relate:
That batch-rel-ops implementation is using cypher because while I can create a new relationship using the {id-number}/relationships REST end point, I didn’t immediately see a way to tell to create a new one. I’ve decided to batch a cypher query while I do my performance tests and look for an alternative after I’ve got some tests around it.
…
Interesting. The Neo4j batch API only accepts positive integers for the request reference ID. It would be nice if that were obviously documented, since there is no particular reason why - it’s after all just a reference. If it wasn’t going to take negative integers, it could at least take longs.
…
Fascinating. I ran into this during testing.
Suppose the two equivalent queries:
MATCH ()-[r]->() RETURN DISTINCT r
MATCH (n:Article)-[r]->(m:Article) RETURN DISTINCT r
They’re being executed on an almost empty database (4 nodes, 5 relationships) and neither is using an index. I’m calling both using neocons’ cypher querying, profiling with timbre.
The first one is profiled at 3.1 seconds, the second at 18ms. I haven’t the foggiest as to why.
…
And we’re done lumping the majority of these changes into a single, batched REST call.
The results
After some massive code surgery, we can now import a page with 1880 links to the same Docker container on about 15 seconds… which was what Cowboy Bebop took after our previous semi-batched changes.
Hmpf.
OK, still a wee bit of an improvement, since we get to import about 2x as many links, but not significant enough. This is probably because I am creating the relationships using a Cypher query, since (as far as I know) we can’t create unique relationships using the relationships REST end point. We need to improve this by adding an index, now that we can actually take advantage of it.
So let’s see. If we do a…
CREATE INDEX ON :Article(code)
then the batch insert of 1880 nodes and their relationships goes down from 15 seconds to 5.8s. Moreover, importing our top 10 pages (a total of about 15k nodes, 15k label assignments and 16k relationships) takes only 30s.
That’s more like it.
While on the surface it would look like we’re still down to only 20 pages imported per minute, there’s several things to consider:
- That’s on a test Docker container which is only using two cores (even though increasing the number of cores available to the container doesn’t seem to make much difference for a single batch request);
- Only some of that cost comes from Neo4j, with another chunk of it coming from some Clojure filtering and mapping that I can likely improve;
- Querying for existing nodes once we have indices in is fast;
- This is likely the heaviest insert that the system will see, since other pages don’t have as many outgoing links (95% of the currently imported ones have less than 450);
- The more pages we have imported, the more we’ll just need to reference existing nodes;
Sure, some queries like the one necessary for creating the relationships will have to deal with many more nodes on the live site, but since we’re doing joins on indexes they should be efficient.
Good old Cowboy Bebop, which initially had a test environment import cost of 52 seconds, is now down to 600ms.
That’s an improvement I can definitely live with.
Next steps
Of course, this was some massive hacking and has only partial test coverage. I now need to fix the tests I have, handle redirects (which I don’t on the current version) and clean up for an initial release.
Meanwhile, any Clojurians more experienced than myself with how to optimize and/or improve the filter operations on the gist above? That’s a good chunk of my total time when dealing with a lot of new nodes, in particular filters which end up being a cartesian product.
More coming soon.